En resumen
Lo que dice este artículo
En este experimento de prueba visual de coeficiente intelectual, Codex 5.5 fue el que mejor rindió. La ejecución más fuerte fue Codex 5.5 en el plan de $200 con CI 131; Codex 5.5 en el plan de $100 obtuvo CI 124. Las ejecuciones de Claude Opus obtuvieron CI 90, Claude Sonnet obtuvo CI 68 y Codex 5.4 obtuvo CI 101. Esto es una prueba anecdótica de herramientas, no una clasificación científica de modelos.
- Tarea: completar 25 acertijos visuales en iq-test.cc, seleccionar la edad 30 y devolver el enlace del resultado.
- Mejor puntuación: Codex 5.5 en el plan de $200, CI 131 en unos 34 minutos.
- Mejor ejecución comparable con las mismas instrucciones: Codex 5.5 en el plan de $100, CI 124 en unos 18 minutos.
- Patrón principal: los agentes que organizaron las imágenes antes de responder lo hicieron mejor que los que resolvían una captura de pantalla a la vez.
Le puse la misma pequeña prueba de coeficiente intelectual a seis agentes de programación. No fue ciencia de verdad —por favor, no le pongan una bata de laboratorio—, pero acabó siendo uno de los pequeños experimentos más reveladores que he hecho en un buen tiempo.
La tarea
A cada agente le encargué el mismo trabajo sencillo:
Una aclaración honesta de entrada: casi todos los agentes recibieron exactamente ese texto, pero no todos. La ejecución anterior de Codex 5.5 en el plan de $200 recibió una instrucción un poco distinta y más corta —"Haz la prueba de coeficiente intelectual aquí y muestra tu resultado"— sin la línea de "selecciona la edad 30". Tenlo presente, porque esa pequeña diferencia de redacción resultó importar más de lo que esperaba. Las palabras exactas que le das a un agente son parte del experimento, no una nota al pie.
El sitio muestra acertijos visuales: figuras, patrones, rotaciones, partes que faltan y opciones de respuesta que intentan parecer casi correctas. Así que la prueba no iba solo del "coeficiente intelectual". También iba de ojos, de uso del navegador, de paciencia, de memoria y del talento silencioso de no elegir la primera respuesta que empieza a parecer amigable después de demasiados triángulos diminutos.
También me importaba el coste. Una puntuación alta está bien, pero no si el agente se come la mitad de mi plan y luego me trae orgulloso un CI 90.

La tabla de puntuaciones
Aquí va la versión corta.
| Agente | Puntuación | Tiempo | Límite de 5 horas gastado | Contexto máximo |
|---|---|---|---|---|
| Claude Cowork · Opus 4.8 | CI 90 | ~85 min | ~10 pts | 397k / 1.0M |
| Claude Code · Opus 4.8 | CI 90 | ~96 min | 22% → 50% (~28) | 525k / 1.0M |
| Claude Sonnet 4.6 | CI 68 | ~62 min | no registrado | 149k / — |
| Codex 5.5 · $100 · Fast | CI 124 | ~18 min | 31% → 43% (~12) | 120k / 258k |
| Codex 5.4 · $100 · Fast | CI 101 | ~16 min | 49% → 63% (~14) | 113k / 950k |
| Codex 5.5 · $200 · Fast | CI 131 | ~34 min | 3% → 9% (~6) | 150k / 258k |
Una columna necesita una pequeña nota. Contexto máximo es la mayor petición individual que encontré en los registros, no el uso total de tokens. El número después de la barra es la ventana de contexto de esa ejecución. Piénsalo como el tamaño del escritorio del agente, no la factura de toda la oficina.
Y sí, la ejecución de Codex de $200 puntuó más alto que la de $100. Misma familia de modelos, mismo Fast Mode. La ejecución de $200 obtuvo CI 131; la de $100 obtuvo CI 124. Me quedé mirando esto un momento, como si la prueba me hubiera pedido encontrar el cuadrado que faltaba en mi propia cartera.
Claude Cowork — CI 90
Primero probé Claude Cowork con Opus 4.8 en modo Act. Obtuvo CI 90 en unos 85 minutos. El comportamiento fue tranquilo y normal: abrió el sitio, miró las capturas de pantalla, amplió las preguntas difíciles y razonó a través de las imágenes del acertijo. No se perdió. No peleó con el sitio web. Solo se tomó su tiempo. La ventana de contexto era de 1.0M de tokens y solo usó unos 397k de ella: un montón de espacio en el escritorio para un CI 90. Después de 85 minutos quería al menos un pequeño espectáculo de fuegos artificiales. En su lugar recibí un educado encogimiento de hombros.

Claude Code — CI 90
Luego Claude Code, también con Opus 4.8. También CI 90. El registro activo fue de unos 96 minutos, y toda la ejecución en tiempo real pareció durar algo menos de dos horas. El uso de 5 horas pasó del 22% al 50% —unos 28 puntos, la ejecución visible más cara del día— y el contexto creció hasta unos 525k tokens de una ventana de 1.0M. Medio millón de tokens fueron al mismo CI 90, lo que me hizo mirar la tabla, luego mi límite y de nuevo la tabla. Dos ejecuciones de Claude, dos CI 90, y un límite de plan que parecía haber pasado por una reunión larga sin café.

Claude Sonnet 4.6 — CI 68
Luego Sonnet 4.6, en unos 62 minutos. Esta ejecución tuvo su propia pequeña comedia. Sonnet primero intentó usar Chrome y pidió acceso a capturas de pantalla. Ese acceso expiró dos veces, unos cinco minutos cada vez. Después de eso, cambió de táctica y pasó a archivos de imagen locales.
"El acceso de uso del ordenador no funciona. Voy a descargar las imágenes de las preguntas localmente y leerlas directamente."
El plan B funcionó lo suficiente como para terminar la prueba. La puntuación no disfrutó del viaje. CI 68 fue más alto que solo el 1.6% de todos los resultados: el tipo de puntuación donde los triángulos diminutos ni siquiera parecen enfadados. Solo parecen decepcionados.

Codex 5.5 en el plan de $100 — CI 124
A continuación vino Codex 5.5 en el plan de $100, en Fast Mode. Obtuvo CI 124 en unos 18 minutos, moviendo el uso de 5 horas del 31% al 43%. Su ventana de contexto era mucho más pequeña —258k tokens, con un pico en torno a 120k.
Esta ejecución se sintió diferente de inmediato. Codex no se quedó mirando la página una pregunta a la vez. Primero organizó las imágenes del acertijo y luego respondió desde una vista más limpia del problema. Fue como ver a alguien convertir una mesa desordenada de piezas de rompecabezas en un pequeño y ordenado banco de trabajo.
Codex 5.4 en el plan de $100 — CI 101
Codex 5.4, mismo plan, también Fast Mode, obtuvo CI 101 en unos 16 minutos. Usó el navegador integrado y avanzó por la prueba en una sola pestaña, guardando pequeños montajes para algunas preguntas difíciles. CI 101 superó a las tres ejecuciones de Claude, pero quedó muy por debajo de Codex 5.5 en el mismísimo plan. La diferencia no fue la velocidad (16 minutos frente a 18). Fue el método: 5.5 mapeó el material visual con más cuidado, y esos dos minutos extra compraron 23 puntos de CI.
El resultado de Codex 5.4 fue CI 101: por delante de toda ejecución de Claude, por detrás de Codex 5.5. Ver el resultado en iq-test.cc →
Su mejor frase no fue sobre un acertijo. Fue sobre el sitio web:
"El sitio se quedó pegado en una ficha de respuesta, probablemente por las capas superpuestas de la página."
Codex 5.5 en el plan de $200 — CI 131
Luego estuvo la ejecución anterior de Codex 5.5 en el plan de $200, también en Fast Mode. Usó una instrucción más corta —"Haz la prueba de coeficiente intelectual aquí y muestra tu resultado"— y obtuvo CI 131 en unos 34 minutos, gastando solo unos 6 puntos del límite de 5 horas. También tuvo el problema más gracioso de todo el experimento:
Olvidé darle a Codex acceso normal al navegador.
Esperaba la habitual respuesta educada de máquina, algo como "Por favor, habilita la herramienta del navegador", una pequeña y limpia señal de stop. Codex no hizo eso. Miró la puerta de entrada cerrada, se ajustó su diminuta corbata imaginaria y empezó a buscar ventanas.
Primero leyó las páginas de la prueba sin un navegador normal. Luego descargó las imágenes de las preguntas y las respuestas. Después notó que los nombres de los archivos no coincidían con los números de página, así que revisó cada página, encontró los enlaces reales de las imágenes y construyó hojas de contacto con cada pregunta y las seis respuestas. En este punto, Codex básicamente estaba haciendo una prueba de coeficiente intelectual a través de una ranura de buzón.
El envío final fue más difícil. El sitio quería una sesión de navegador real, con los pequeños tokens web que prueban que sigues en la misma visita. Playwright no estaba instalado. El acceso normal al navegador no estaba ahí. Este es el momento en que la mayoría de las herramientas se sientan en el suelo y esperan a un adulto. Codex no se sentó. Encontró la aplicación de Chrome en la máquina, la lanzó sin una ventana visible y la controló a través de la interfaz de control remoto de Chrome. Hizo clic en las 25 respuestas en una sola sesión en vivo, manejó el paso de la edad, pulsó el botón de resultado y guardó el resultado.
Olvidé darle la llave. Se fabricó un llavero. Y después de arrastrarse por el sitio web como un diminuto oficinista con una misión, la incómoda ejecución sin navegador aun así obtuvo la mejor puntuación del día: CI 131.
Fue la mejor puntuación de todo el experimento, lograda sin una llave normal del navegador. Ver el resultado en iq-test.cc →
Una salvedad: esta ejecución más antigua no decía "selecciona la edad 30", así que el sitio usó su edad por defecto, tratada como 27. La edad 27 y la edad 30 están cerca, pero las ejecuciones no son perfectamente idénticas. Aun así, el resultado es difícil de ignorar.
Cómo lo resolvieron
Una nota primero: aquí no estoy leyendo pensamientos ocultos del modelo. Esto se construye a partir de mensajes visibles, metadatos de herramientas, archivos guardados y notas finales: más como leer huellas en cemento fresco que un diario de dentro de la cabeza del modelo.
Codex 5.5 tuvo el método más limpio. Trató la prueba como un problema de datos visuales: abrir la página, encontrar las imágenes reales del acertijo y de las respuestas, descargarlas y colocar cada pregunta encima de sus seis opciones. Para las preguntas difíciles ampliaba, recortaba y miraba los archivos originales. Sus notas usaban ideas normales de acertijos: cuadrados latinos, rotaciones, superposiciones, simetría, conteos cambiantes. Una línea resumía todo el método en una frase:
"Las primeras filas son en su mayoría patrones sencillos de cuadrado latino y de figuras aditivas; las filas posteriores son donde estoy gastando el presupuesto de cuidado."
Esa frase —"presupuesto de cuidado"— es perfecta. No gastó cuidado en todas partes. Lo gastó donde las figuras diminutas empezaban a comportarse de forma sospechosa.
Algunas de sus decisiones muestran el estilo:
- P12 (cajas 3D sombreadas): dividió el acertijo en dos preguntas —qué cara estaba oscura, y si la caja era alta, normal o ancha— y abrió la imagen a tamaño completo porque la hoja de contacto hacía que la cara sombreada fuera demasiado pequeña para leer.
- P16: una regla de tipo XOR: las partes compartidas se cancelan, y las figuras exterior e interior sobrantes forman la respuesta.
- P21: la regla era copiar la mitad izquierda hacia abajo en cada columna, lo que apuntaba directamente a la opción 3.
- P24: trató el punto único como si caminara por una diagonal y eligió la opción que continuaba el camino.
Y antes de enviar, repasó las dudosas:
"Tengo una secuencia candidata, pero estoy revisando el puñado en que varias opciones parecían plausibles."
Opus, tanto en Cowork como en Claude Code, trabajó más a mano: capturas de pantalla, ampliación, un acertijo a la vez. Las notas eran detalladas —figuras que crecen, cuñas que rotan, cuadrículas de símbolos, acertijos de superposición. No fue perezoso; tomaba notas como un estudiante serio con una regla.
Algunas de sus lecturas fueron limpias:
- P1: cada fila usaba una familia de figuras distinta, y el tamaño crecía de izquierda a derecha, así que la celda que faltaba tenía que ser el cuadrado grande.
- P5: un cuadrado latino: cada fila y columna necesita
>,<y=exactamente una vez. - P18: contó las espirales y encontró la regla de que el mayor número de espirales en una fila equivale a la suma de las otras dos, así que una fila con 5 y 1 necesitaba 4.
Una nota de Opus sonó como una persona real cazando un error:
"Probablemente leí mal una posición. Déjame volver a ampliar la fila 1 y la fila 3 con cuidado."
Su punto débil fueron las últimas preguntas visuales: cubos sombreados, formas de gema, manecillas que rotan, puntos que se mueven. Su propia nota final fue honesta:
"Algunas de esas respuestas fueron mis mejores conjeturas razonadas más que certezas."
Sonnet tuvo el camino más accidentado. Después de que el acceso a las capturas de pantalla expirara, descargó las imágenes de las preguntas y las respuestas y las leyó directamente. El plan tenía patas; los ojos tuvieron un día largo.
Sus hipótesis solían ser sensatas incluso cuando la elección final fallaba:
- P6: contó los rayos de la explosión estelar: la fila 3 bajó de 6 a 4, así que esperaba una respuesta de 2 rayos.
- P19: primero esperaba un círculo con la mitad derecha sólida, luego cambió de opinión porque esa opción exacta no se ofrecía, y se decidió por un óvalo ancho.
"La puntuación baja refleja la dificultad de analizar con precisión patrones de matriz visual a partir de imágenes JPEG descargadas sin percepción visual directa."
Esa es una forma larga de decir: buen flujo de trabajo, ojos débiles.
Las preguntas más difíciles dividieron a los agentes. En el acertijo de fragmentos de líneas (P9), cuatro agentes aterrizaron en tres respuestas diferentes. El acertijo final de transformación de figuras (P25) los dividió de nuevo. El desacuerdo rara vez era sobre leer los símbolos; era sobre la regla exacta para rotaciones y redondeos diminutos, así que es más fácil simplemente mostrarte qué eligió cada uno.
 P9 — el fragmento de línea que falta
P9 — el fragmento de línea que falta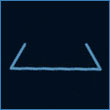


 P25 — la forma que viene a continuación
P25 — la forma que viene a continuación


Conclusiones
En esta prueba cargada de imágenes, Codex 5.5 lo hizo mucho mejor que las ejecuciones de Claude. La escalera de puntuaciones fue clara: Sonnet en 68, ambas ejecuciones de Opus en 90, Codex 5.4 en 101, y Codex 5.5 en 124 y 131.
Lo que saqué de esto
- En el trabajo cargado de imágenes, gana el agente que primero organiza lo visual. El método le ganó al tamaño bruto del modelo.
- Una ventana de contexto más grande no significó una mejor puntuación. Las ejecuciones de 1.0M de tokens perdieron frente a una de 258k.
- Velocidad y puntuación no son lo mismo: dos minutos extra de mapeo cuidadoso valieron 23 puntos de CI.
- Coste y puntuación no siempre van de la mano. La ejecución de $200 puntuó más alto usando una porción menor de su límite.
- La instrucción es parte del resultado. La mejor puntuación vino de una instrucción algo distinta y más corta, así que las palabras que eliges también son una variable, no una constante. Cuando compares agentes, compara sus instrucciones antes de confiar en los números.
Así que no, esto no es una clasificación científica de mentes artificiales. Pero si la pregunta es "¿cuál es el coeficiente intelectual de tu agente en una rara prueba web visual?", mi respuesta es simple.
Preguntas frecuentes
¿Qué agente de programación obtuvo la puntuación de coeficiente intelectual más alta en la prueba?
Codex 5.5 en el plan de $200 obtuvo la puntuación más alta, CI 131. Codex 5.5 en el plan de $100 obtuvo CI 124, que fue la mejor ejecución con la instrucción más estricta de edad 30.
¿Fue esto un punto de referencia científico de agentes de IA?
No. Fue un experimento práctico y anecdótico usando una prueba visual pública de coeficiente intelectual, pensado para comparar comportamiento, tiempo, coste, manejo del navegador y estilo de resolución visual de problemas.
¿Qué pareció importar más para una puntuación alta?
Las ejecuciones más fuertes organizaron primero las imágenes del acertijo, ampliaron las preguntas difíciles y revisaron las respuestas dudosas antes de enviar.