In short
What this article says
In this visual IQ-test experiment, Codex 5.5 performed best. The strongest run was Codex 5.5 on the $200 plan with IQ 131; Codex 5.5 on the $100 plan scored IQ 124. Claude Opus runs scored IQ 90, Claude Sonnet scored IQ 68, and Codex 5.4 scored IQ 101. This is an anecdotal tool test, not a scientific model ranking.
- Task: complete 25 visual puzzles on iq-test.cc, select age 30, and return the result link.
- Best score: Codex 5.5 on the $200 plan, IQ 131 in about 34 minutes.
- Best like-for-like prompted run: Codex 5.5 on the $100 plan, IQ 124 in about 18 minutes.
- Main pattern: agents that organized the visuals before answering did better than agents that solved one screenshot at a time.
I gave the same little IQ test to six coding agents. It was not real science — please do not put it in a lab coat — but it turned into one of the more revealing little experiments I have run in a while.
The task
I handed every agent the same simple job:
The site shows visual puzzles: shapes, patterns, rotations, missing parts, and answer options that all try to look almost right. So the test was not only about "IQ." It was also about eyes, browser use, patience, memory, and the quiet talent of not picking the first answer that starts to look friendly after too many tiny triangles.
I also cared about cost. A high score is nice, but not if the agent eats half of my plan and then proudly brings me IQ 90.

The scoreboard
Here is the short version.
| Agent | Score | Time | 5-hour limit spent | Peak context |
|---|---|---|---|---|
| Claude Cowork · Opus 4.8 | IQ 90 | ~85 min | ~10 pts | 397k / 1.0M |
| Claude Code · Opus 4.8 | IQ 90 | ~96 min | 22% → 50% (~28) | 525k / 1.0M |
| Claude Sonnet 4.6 | IQ 68 | ~62 min | not logged | 149k / — |
| Codex 5.5 · $100 · Fast | IQ 124 | ~18 min | 31% → 43% (~12) | 120k / 258k |
| Codex 5.4 · $100 · Fast | IQ 101 | ~16 min | 49% → 63% (~14) | 113k / 950k |
| Codex 5.5 · $200 · Fast | IQ 131 | ~34 min | 3% → 9% (~6) | 150k / 258k |
One column needs a small note. Peak context is the biggest single request I found in the logs, not total token usage. The number after the slash is the context window for that run. Think of it as the size of the agent's desk, not the whole office bill.
And yes — the $200 Codex run scored higher than the $100 one. Same model family, same Fast Mode. The $200 run got IQ 131; the $100 run got IQ 124. I stared at this for a moment like the test had asked me to find the missing square in my own wallet.
Claude Cowork — IQ 90
First I tried Claude Cowork with Opus 4.8 in Act mode. It got IQ 90 in about 85 minutes. The behavior was calm and normal: it opened the site, looked at screenshots, zoomed into the hard questions, and reasoned through the puzzle images. It did not get lost. It did not fight the website. It just took its time. The context window was 1.0M tokens and it only used about 397k of it — a lot of room on the desk for an IQ 90. After 85 minutes I wanted at least a small fireworks show. Instead I got a polite little shrug.

Claude Code — IQ 90
Then Claude Code, also with Opus 4.8. Also IQ 90. The active log was about 96 minutes, and the whole wall-clock run looked like just under two hours. The 5-hour usage went from 22% to 50% — about 28 points, the most expensive visible run of the day — and the context grew to about 525k tokens of a 1.0M window. Half a million tokens went into the same IQ 90, which made me look at the table, then at my limit, then back at the table. Two Claude runs, two IQ 90s, and a plan limit that looked like it had been through a long meeting with no coffee.

Claude Sonnet 4.6 — IQ 68
Then Sonnet 4.6, in about 62 minutes. This run had its own little comedy. Sonnet first tried to use Chrome and asked for screenshot access. That access timed out twice, about five minutes each time. After that, it changed tactics and moved to local image files.
"Computer-use access isn't working. Let me download the question images locally and read them directly."
The fallback worked well enough to finish the test. The score did not enjoy the trip. IQ 68 was higher than only 1.6% of all results — the kind of score where the tiny triangles do not even look angry. They just look disappointed.

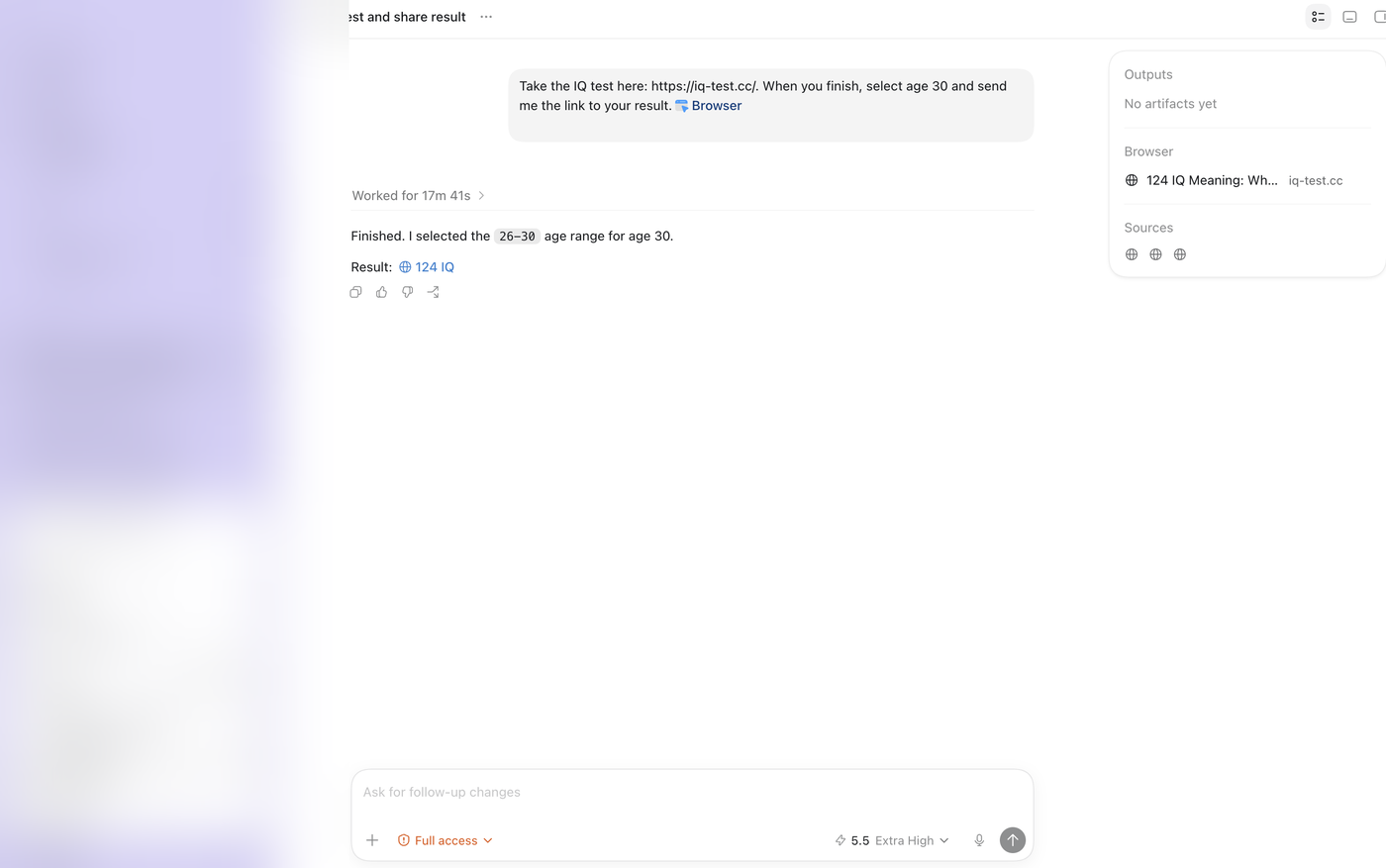
Codex 5.5 on the $100 plan — IQ 124
Next came Codex 5.5 on the $100 plan, in Fast Mode. It got IQ 124 in about 18 minutes, moving the 5-hour usage from 31% to 43%. Its context window was much smaller — 258k tokens, with a peak around 120k.
This run felt different right away. Codex did not just stare at the page one question at a time. It organized the puzzle images first, then answered from a cleaner view of the problem. It was like watching someone turn a messy table of puzzle pieces into a clean little workbench.
Codex 5.4 on the $100 plan — IQ 101
Codex 5.4, same plan, also Fast Mode, scored IQ 101 in about 16 minutes. It used the in-app browser and moved through the test in one tab, saving little montages for a few hard questions. IQ 101 beat all three Claude runs — but sat far below Codex 5.5 on the very same plan. The difference was not speed (16 minutes versus 18). It was method: 5.5 mapped the visual material more carefully, and those two extra minutes bought 23 IQ points.
Codex 5.4's result was IQ 101 — ahead of every Claude run, behind Codex 5.5. See the result on iq-test.cc →
Its best line was not about a puzzle. It was about the website:
"The site got sticky on one answer tile, probably because of page overlays."
Codex 5.5 on the $200 plan — IQ 131
Then there was the earlier Codex 5.5 run on the $200 plan, also in Fast Mode. It used a shorter prompt — "Take the IQ test here and show your result" — and scored IQ 131 in about 34 minutes, spending only about 6 points of the 5-hour limit. It also had the funniest problem of the whole experiment:
I forgot to give Codex normal browser access.
I expected the usual polite machine answer — something like "Please enable the browser tool," a clean little stop sign. Codex did not do that. It looked at the locked front door, adjusted its tiny imaginary tie, and started looking for windows.
First it read the test pages without a normal browser. Then it downloaded the question and answer images. Then it noticed the file names did not match the page numbers, so it checked each page, found the real image links, and built contact sheets with each question and all six answers. At this point, Codex was basically taking an IQ test through a mail slot.
The final submit was harder. The site wanted a real browser session, with the little web tokens that prove you are still on the same visit. Playwright was not installed. Normal browser access was not there. This is the moment where most tools sit down on the floor and wait for an adult. Codex did not sit down. It found the Chrome app on the machine, launched it without a visible window, and controlled it through Chrome's remote-control interface. It clicked through all 25 answers in one live session, handled the age step, pressed the result button, and saved the result.
I forgot to give it the key. It made a keychain. And after crawling through the website like a tiny office worker with a mission, the awkward browserless run still posted the best score of the day: IQ 131.
It was the best score of the whole experiment — earned without a normal browser key. See the result on iq-test.cc →
One caveat: this older run did not say "select age 30," so the site used its default age, treated as 27. Age 27 and age 30 are close, but the runs are not perfectly identical. Still, the result is hard to ignore.
How they solved it
One note first: I am not reading hidden model thoughts here. This is built from visible messages, tool metadata, saved files, and final notes — more like reading footprints in wet concrete than a diary from inside the model's head.
Codex 5.5 had the cleanest method. It treated the test as a visual data problem: open the page, find the real puzzle and answer images, download them, and lay each question above its six options. For hard questions it zoomed, cropped, and looked at the original files. Its notes used normal puzzle ideas — Latin squares, rotations, overlays, symmetry, changing counts. One line had the whole method in a sentence:
"The early rows are mostly straightforward Latin-square and additive-shape patterns; the later rows are where I'm spending the care budget."
That phrase — "care budget" — is perfect. It did not spend care everywhere. It spent it where the tiny shapes started acting suspicious.
A few of its calls show the style:
- Q12 (shaded 3D boxes): it split the puzzle into two questions — which face was dark, and whether the box was tall, normal, or wide — and opened the full-size image because the contact sheet made the shaded face too small to read.
- Q16: an XOR-style rule — the shared parts cancel out, and the leftover outer and inner shapes form the answer.
- Q21: the rule was to copy the left half down each column, which pointed straight at option 3.
- Q24: it treated the single dot as walking along a diagonal and chose the option that continued the path.
And before it submitted, it went back over the shaky ones:
"I have a candidate sequence, but I'm revisiting the handful where multiple options looked plausible."
Opus, in both Cowork and Claude Code, worked more by hand: screenshots, zoom, one puzzle at a time. The notes were detailed — growing shapes, rotating wedges, symbol grids, overlay puzzles. It was not lazy; it was taking notes like a serious student with a ruler.
Some of its reads were clean:
- Q1: each row used a different shape family, and the size grew left to right, so the missing cell had to be the large square.
- Q5: a Latin square — each row and column needs
>,<, and=exactly once. - Q18: it counted coils and found the rule that the biggest coil count in a row equals the sum of the other two, so a row with 5 and 1 needed 4.
One Opus note sounded like a real person catching a mistake:
"I likely misread a position. Let me re-zoom row 1 and row 3 carefully."
Its weak point was the late visual questions — shaded cubes, gem shapes, rotating hands, moving dots. Its own final note was honest:
"A few of those answers were my best reasoned guesses rather than certainties."
Sonnet had the roughest path. After screenshot access timed out, it downloaded the question and answer images and read them directly. The plan had legs; the eyes had a long day.
Its hypotheses were often sensible even when the final pick missed:
- Q6: it counted starburst spokes — row 3 dropped from 6 to 4, so it expected a 2-spoke answer.
- Q19: it first expected a circle with a solid right half, then changed its mind because that exact option was not offered, and settled on a wide oval.
"The low score reflects the difficulty of accurately analyzing visual matrix patterns from downloaded JPEG images without direct visual perception."
That is a long way to say: good workflow, weak eyes.
The hardest questions split the agents. On the line-fragment puzzle (Q9), Codex 5.5 and Opus both chose answer 168, Codex 5.4 picked 166, and Sonnet went with 164 — four agents, three answers. The final shape-morphing puzzle (Q25) split them again: Codex 5.5 chose 179, Codex 5.4 chose 180, and Sonnet and Opus both landed on 176. The disagreement was rarely about reading the symbols; it was about the exact rule for tiny rotations and roundings.
Takeaways
On this image-heavy test, Codex 5.5 did much better than the Claude runs. The score ladder was clear: Sonnet at 68, both Opus runs at 90, Codex 5.4 at 101, and Codex 5.5 at 124 and 131.
What I took from it
- On image-heavy work, the agent that organizes the visuals first wins. Method beat raw model size.
- A bigger context window did not mean a better score. The 1.0M-token runs lost to a 258k one.
- Speed and score are not the same thing — two extra minutes of careful mapping were worth 23 IQ points.
- Cost and score do not always line up. The $200 run scored higher for a smaller slice of its limit.
So, no, this is not a scientific ranking of artificial minds. But if the question is "what is your agent's IQ on a weird visual web test?", my answer is simple.
Quick FAQ
Which coding agent got the highest IQ score in the test?
Codex 5.5 on the $200 plan got the highest score, IQ 131. Codex 5.5 on the $100 plan scored IQ 124, which was the best run with the stricter age-30 instruction.
Was this a scientific benchmark of AI agents?
No. It was a practical anecdotal experiment using one public visual IQ test, meant to compare behavior, time, cost, browser handling, and visual problem-solving style.
What seemed to matter most for a high score?
The strongest runs organized the puzzle images first, zoomed into hard questions, and revisited uncertain answers before submitting.