باختصار
ما الذي تقوله هذه المقالة
في تجربة اختبار الذكاء البصري هذه، كان أداء Codex 5.5 هو الأفضل. كانت أقوى جولة هي Codex 5.5 على خطة الـ$200 بمعدل ذكاء IQ 131؛ وحصل Codex 5.5 على خطة الـ$100 على IQ 124. حصلت جولات Claude Opus على IQ 90، وحصل Claude Sonnet على IQ 68، وحصل Codex 5.4 على IQ 101. هذه تجربة عملية لأداة، وليست تصنيفًا علميًا للنماذج.
- المهمة: إكمال 25 لغزًا بصريًا على iq-test.cc، واختيار سن 30، وإعادة رابط النتيجة.
- أفضل نتيجة: Codex 5.5 على خطة الـ$200 بمعدل IQ 131 في نحو 34 دقيقة.
- أفضل جولة متماثلة بنفس التوجيه: Codex 5.5 على خطة الـ$100 بمعدل IQ 124 في نحو 18 دقيقة.
- النمط الرئيسي: الوكلاء الذين نظّموا الصور البصرية قبل الإجابة كان أداؤهم أفضل من الوكلاء الذين حلّوا لقطة شاشة واحدة في كل مرة.
أجريت اختبار الذكاء الصغير نفسه على ستة وكلاء برمجة. لم يكن علمًا حقيقيًا — أرجوكم لا تُلبسوه معطفًا مخبريًا — لكنه تحوّل إلى واحدة من أكثر التجارب الصغيرة كشفًا التي أجريتها منذ فترة.
المهمة
أعطيت كل وكيل المهمة البسيطة نفسها:
تنويه صادق منذ البداية: حصل كل وكيل تقريبًا على هذه الصياغة بالضبط، لكن ليس جميعهم. الجولة الأسبق من Codex 5.5 على خطة الـ$200 حصلت على موجّه مختلف قليلًا وأقصر — "اخضع لاختبار الذكاء هنا وأظهر نتيجتك" — من دون سطر "اختر سن 30". احتفظ بهذا في ذهنك، لأن الفارق الصغير في الصياغة تبيّن أنه أهم مما توقعت. الكلمات الدقيقة التي تعطيها لوكيل جزء من التجربة، لا حاشية لها.
يعرض الموقع ألغازًا بصرية: أشكال وأنماط ودورات وأجزاء ناقصة، وخيارات إجابة يحاول كلٌّ منها أن يبدو شبه صحيح. لذا لم يكن الاختبار عن "الذكاء" فقط. كان أيضًا عن العين، واستخدام المتصفح، والصبر، والذاكرة، والموهبة الهادئة في عدم اختيار أول إجابة تبدأ بالظهور ودودة بعد عدد كبير جدًا من المثلثات الصغيرة.
كنت أهتم بالتكلفة أيضًا. النتيجة العالية لطيفة، لكن ليس حين يلتهم الوكيل نصف خطتي ثم يأتيني بفخر بمعدل ذكاء IQ 90.

لوحة النتائج
إليك النسخة المختصرة.
| الوكيل | النتيجة | الوقت | المستهلَك من حد الـ5 ساعات | ذروة السياق |
|---|---|---|---|---|
| Claude Cowork · Opus 4.8 | IQ 90 | ~85 دقيقة | ~10 نقاط | 397k / 1.0M |
| Claude Code · Opus 4.8 | IQ 90 | ~96 دقيقة | 22% → 50% (~28) | 525k / 1.0M |
| Claude Sonnet 4.6 | IQ 68 | ~62 دقيقة | غير مسجّل | 149k / — |
| Codex 5.5 · $100 · Fast | IQ 124 | ~18 دقيقة | 31% → 43% (~12) | 120k / 258k |
| Codex 5.4 · $100 · Fast | IQ 101 | ~16 دقيقة | 49% → 63% (~14) | 113k / 950k |
| Codex 5.5 · $200 · Fast | IQ 131 | ~34 دقيقة | 3% → 9% (~6) | 150k / 258k |
عمود واحد يحتاج إلى ملاحظة صغيرة. ذروة السياق هي أكبر طلب مفرد وجدته في السجلات، لا إجمالي استهلاك الرموز. الرقم بعد الشرطة المائلة هو نافذة السياق لتلك الجولة. اعتبره حجم مكتب الوكيل، لا فاتورة المكتب كاملةً.
ونعم — جولة Codex على خطة الـ$200 سجّلت أعلى من جولة الـ$100. العائلة نفسها من النماذج، والوضع Fast Mode نفسه. حصلت جولة الـ$200 على IQ 131؛ وحصلت جولة الـ$100 على IQ 124. حدّقت في هذا لحظة كأن الاختبار طلب مني أن أجد المربع الناقص في محفظتي.
Claude Cowork — IQ 90
أولًا جرّبت Claude Cowork مع Opus 4.8 في وضع Act. حصل على IQ 90 في نحو 85 دقيقة. كان سلوكه هادئًا واعتياديًا: فتح الموقع، ونظر إلى لقطات الشاشة، وكبّر الأسئلة الصعبة، واستدل عبر صور الألغاز. لم يتُه. لم يتشاجر مع الموقع. أخذ وقته فحسب. كانت نافذة السياق 1.0M رمز ولم يستخدم منها سوى نحو 397k — مساحة كبيرة على المكتب مقابل IQ 90. بعد 85 دقيقة أردت ولو عرضًا صغيرًا من الألعاب النارية. وبدلًا من ذلك حصلت على هزّة كتفين مهذبة صغيرة.

Claude Code — IQ 90
ثم Claude Code، أيضًا مع Opus 4.8. أيضًا IQ 90. استغرق السجل النشط نحو 96 دقيقة، وبدت الجولة كاملةً بحسب الساعة أقل بقليل من ساعتين. ارتفع استهلاك حد الـ5 ساعات من 22% إلى 50% — نحو 28 نقطة، أغلى جولة ظاهرة في اليوم — ونما السياق إلى نحو 525k رمز من نافذة 1.0M. ذهب نصف مليون رمز إلى الـIQ 90 نفسه، ما جعلني أنظر إلى الجدول، ثم إلى حدّي، ثم أعود إلى الجدول. جولتان من Claude، واثنتان بـIQ 90، وحد خطة يبدو وكأنه خرج من اجتماع طويل بلا قهوة.

Claude Sonnet 4.6 — IQ 68
ثم Sonnet 4.6، في نحو 62 دقيقة. كانت لهذه الجولة كوميديا صغيرة خاصة بها. حاول Sonnet أولًا استخدام Chrome وطلب صلاحية لقطات الشاشة. انتهت تلك الصلاحية بالمهلة مرتين، نحو خمس دقائق في كل مرة. بعد ذلك، غيّر تكتيكه وانتقل إلى ملفات الصور المحلية.
"صلاحية computer-use لا تعمل. دعني أنزّل صور الأسئلة محليًا وأقرأها مباشرةً."
نجح البديل بما يكفي لإنهاء الاختبار. لكن النتيجة لم تستمتع بالرحلة. كان IQ 68 أعلى من 1.6% فقط من جميع النتائج — من النوع الذي لا تبدو فيه المثلثات الصغيرة غاضبة حتى. تبدو فقط محبَطة.

Codex 5.5 على خطة الـ$100 — IQ 124
تلا ذلك Codex 5.5 على خطة الـ$100، في Fast Mode. حصل على IQ 124 في نحو 18 دقيقة، محرّكًا استهلاك حد الـ5 ساعات من 31% إلى 43%. كانت نافذة سياقه أصغر بكثير — 258k رمز، بذروة نحو 120k.
أحسست بأن هذه الجولة مختلفة فورًا. لم يكتفِ Codex بالتحديق في الصفحة سؤالًا واحدًا في كل مرة. نظّم صور الألغاز أولًا، ثم أجاب من رؤية أوضح للمشكلة. كان الأمر أشبه بمشاهدة شخص يحوّل طاولة فوضوية مليئة بقطع الألغاز إلى منضدة عمل صغيرة مرتّبة.
Codex 5.4 على خطة الـ$100 — IQ 101
Codex 5.4، الخطة نفسها، وأيضًا Fast Mode، سجّل IQ 101 في نحو 16 دقيقة. استخدم المتصفح المدمج في التطبيق ومرّ عبر الاختبار في علامة تبويب واحدة، مع حفظ مونتاجات صغيرة لبضعة أسئلة صعبة. تفوّق IQ 101 على جولات Claude الثلاث جميعها — لكنه جلس أدنى بكثير من Codex 5.5 على الخطة نفسها تمامًا. لم يكن الفارق في السرعة (16 دقيقة مقابل 18). كان في المنهج: نظّم 5.5 المادة البصرية بعناية أكبر، واشترت تلك الدقيقتان الإضافيتان 23 نقطة IQ.
كانت نتيجة Codex 5.4 هي IQ 101 — متقدّمًا على كل جولات Claude، ومتأخرًا عن Codex 5.5. شاهد النتيجة على iq-test.cc ←
أفضل عباراته لم تكن عن لغز. كانت عن الموقع:
"علِق الموقع على إحدى بطاقات الإجابة، على الأرجح بسبب طبقات تراكب الصفحة."
Codex 5.5 على خطة الـ$200 — IQ 131
ثم كانت هناك جولة Codex 5.5 الأسبق على خطة الـ$200، أيضًا في Fast Mode. استخدمت موجّهًا أقصر — "اخضع لاختبار الذكاء هنا وأظهر نتيجتك" — وسجّلت IQ 131 في نحو 34 دقيقة، مع إنفاق نحو 6 نقاط فقط من حد الـ5 ساعات. كما كانت لها أطرف مشكلة في التجربة كلها:
نسيت أن أعطي Codex صلاحية وصول عادية إلى المتصفح.
توقّعت الردّ الآلي المهذّب المعتاد — شيئًا مثل "يرجى تفعيل أداة المتصفح"، إشارة توقّف صغيرة نظيفة. لم يفعل Codex ذلك. نظر إلى الباب الأمامي المقفل، عدّل ربطة عنقه الوهمية الصغيرة، وبدأ يبحث عن النوافذ.
أولًا قرأ صفحات الاختبار من دون متصفح عادي. ثم نزّل صور الأسئلة والإجابات. ثم لاحظ أن أسماء الملفات لا تطابق أرقام الصفحات، فتفقّد كل صفحة، ووجد روابط الصور الحقيقية، وبنى أوراق تجميع تضم كل سؤال وإجاباته الست. عند هذه النقطة، كان Codex في الأساس يخضع لاختبار ذكاء عبر فتحة بريد.
كان الإرسال النهائي أصعب. أراد الموقع جلسة متصفح حقيقية، مع تلك الرموز الشبكية الصغيرة التي تثبت أنك لا تزال في الزيارة نفسها. لم يكن Playwright مثبّتًا. ولم تكن صلاحية الوصول العادية إلى المتصفح موجودة. هذه هي اللحظة التي تجلس فيها معظم الأدوات على الأرض وتنتظر شخصًا بالغًا. لم يجلس Codex. وجد تطبيق Chrome على الجهاز، وأطلقه من دون نافذة مرئية، وتحكّم فيه عبر واجهة التحكم عن بُعد في Chrome. نقر عبر كل الإجابات الـ25 في جلسة حيّة واحدة، وتعامل مع خطوة العمر، وضغط زر النتيجة، وحفظ النتيجة.
نسيت أن أعطيه المفتاح. فصنع سلسلة مفاتيح. وبعد أن زحف عبر الموقع كموظف مكتب صغير في مهمة، ما زالت الجولة المحرجة بلا متصفح تنشر أفضل نتيجة في اليوم: IQ 131.
كانت أفضل نتيجة في التجربة كلها — مكتسَبة من دون مفتاح متصفح عادي. شاهد النتيجة على iq-test.cc ←
تنويه واحد: لم تقل هذه الجولة الأقدم "اختر سن 30"، لذا استخدم الموقع عمره الافتراضي، الذي يُعامَل على أنه 27. سن 27 وسن 30 متقاربان، لكن الجولتين ليستا متطابقتين تمامًا. ومع ذلك، يصعب تجاهل النتيجة.
كيف حلّوها
ملاحظة أولًا: أنا لا أقرأ هنا أفكار النماذج الخفية. هذا مبنيٌّ على الرسائل الظاهرة، وبيانات الأدوات الوصفية، والملفات المحفوظة، والملاحظات النهائية — أقرب إلى قراءة آثار الأقدام في الإسمنت الرطب منه إلى يوميات من داخل رأس النموذج.
كان لدى Codex 5.5 أنظف منهج. عامل الاختبار كمشكلة بيانات بصرية: افتح الصفحة، وجد صور الألغاز والإجابات الحقيقية، ونزّلها، وضع كل سؤال فوق خياراته الستة. للأسئلة الصعبة، كبّر وقصّ ونظر إلى الملفات الأصلية. استخدمت ملاحظاته أفكار ألغاز اعتيادية — المربعات اللاتينية، والدورات، والتراكبات، والتناظر، والأعداد المتغيرة. وضع سطرٌ واحد المنهج كله في جملة:
"الصفوف المبكّرة في معظمها أنماط مربعات لاتينية وأشكال جمعية مباشرة؛ والصفوف اللاحقة هي حيث أنفق ميزانية العناية."
تلك العبارة — "ميزانية العناية" — مثالية. لم ينفق العناية في كل مكان. أنفقها حيث بدأت الأشكال الصغيرة تتصرف بريبة.
تُظهر بضعٌ من تعليقاته الأسلوب:
- السؤال 12 (مكعّبات ثلاثية الأبعاد مظلَّلة): قسّم اللغز إلى سؤالين — أيُّ وجه كان داكنًا، وهل كان الصندوق طويلًا أم عاديًا أم عريضًا — وفتح الصورة بالحجم الكامل لأن الوجه المظلَّل بدا في ورقة التجميع أصغر من أن يُقرأ.
- السؤال 16: قاعدة على نمط XOR — تتلاشى الأجزاء المشتركة، وتُكوّن الأشكال الخارجية والداخلية المتبقية الإجابة.
- السؤال 21: كانت القاعدة نسخ النصف الأيسر إلى الأسفل في كل عمود، ما أشار مباشرةً إلى الخيار 3.
- السؤال 24: عامل النقطة المفردة كأنها تسير على طول قطر واختار الخيار الذي يُكمل المسار.
وقبل أن يرسل، عاد إلى المتزعزعة:
"لديّ تسلسل مرشّح، لكنني أراجع تلك الحفنة التي بدت فيها عدة خيارات معقولة."
Opus، في كلٍّ من Cowork وClaude Code، عمل يدويًا أكثر: لقطات شاشة، تكبير، لغز واحد في كل مرة. كانت الملاحظات مفصّلة — أشكال متنامية، وأسافين دوّارة، وشبكات رموز، وألغاز تراكب. لم يكن كسولًا؛ كان يدوّن الملاحظات كطالب جادّ بمسطرة.
كانت بعض قراءاته نظيفة:
- السؤال 1: استخدم كل صف عائلة أشكال مختلفة، ونما الحجم من اليسار إلى اليمين، فكان لا بد أن تكون الخلية الناقصة هي المربع الكبير.
- السؤال 5: مربع لاتيني — يحتاج كل صف وعمود إلى
>و<و=مرة واحدة بالضبط. - السؤال 18: عدّ اللفّات ووجد القاعدة بأن أكبر عدد لفّات في صف يساوي مجموع الاثنين الآخرين، فالصف الذي فيه 5 و1 يحتاج إلى 4.
بدت إحدى ملاحظات Opus كشخص حقيقي يلتقط خطأه:
"يبدو أنني قرأت موقعًا بشكل خاطئ. دعني أعيد تكبير الصف 1 والصف 3 بعناية."
كانت نقطة ضعفه الأسئلة البصرية المتأخرة — المكعّبات المظلَّلة، وأشكال الجواهر، والعقارب الدوّارة، والنقاط المتحركة. كانت ملاحظته النهائية صادقة:
"بعض تلك الإجابات كانت أفضل تخميناتي المُستدَل عليها لا يقينيات."
كان لدى Sonnet أوعر طريق. بعد أن انتهت صلاحية لقطات الشاشة بالمهلة، نزّل صور الأسئلة والإجابات وقرأها مباشرةً. كان للخطة أرجل؛ وللعينين يوم طويل.
كانت فرضياته معقولة في الغالب حتى عندما أخطأ الاختيار النهائي:
- السؤال 6: عدّ أشعّة النجمة المتفجّرة — في الصف 3 انخفضت من 6 إلى 4، فتوقّع إجابة بشعاعين.
- السؤال 19: توقّع أولًا دائرة بنصف أيمن مصمت، ثم غيّر رأيه لأن ذلك الخيار بالضبط لم يكن معروضًا، واستقر على شكل بيضوي عريض.
"تعكس النتيجة المنخفضة صعوبة التحليل الدقيق لأنماط المصفوفات البصرية من صور JPEG المُنزَّلة من دون إدراك بصري مباشر."
هذه طريقة طويلة للقول: سير عمل جيد، عينان ضعيفتان.
قسّمت الأسئلة الأصعب الوكلاء. في لغز شظايا الخطوط (السؤال 9)، استقر أربعة وكلاء على ثلاث إجابات مختلفة. ولغز تشوّه الأشكال النهائي (السؤال 25) قسّمهم مجددًا. نادرًا ما كان الخلاف عن قراءة الرموز؛ كان عن القاعدة الدقيقة للدورات والتدويرات الصغيرة — لذا من الأسهل أن أريك ما اختاره كلٌّ منهم.
 السؤال 9 — شظية الخط الناقصة
السؤال 9 — شظية الخط الناقصة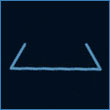


 السؤال 25 — الشكل الذي يأتي بعد ذلك
السؤال 25 — الشكل الذي يأتي بعد ذلك


الخلاصات
في هذا الاختبار المثقل بالصور، كان أداء Codex 5.5 أفضل بكثير من جولات Claude. كان سلّم النتائج واضحًا: Sonnet عند 68، وكلتا جولتي Opus عند 90، وCodex 5.4 عند 101، وCodex 5.5 عند 124 و131.
ما استخلصته منه
- في العمل المثقل بالصور، يفوز الوكيل الذي ينظّم العناصر البصرية أولًا. المنهج تغلّب على حجم النموذج الخام.
- نافذة السياق الأكبر لم تعنِ نتيجة أفضل. خسرت جولات الـ1.0M رمز أمام جولة الـ258k.
- السرعة والنتيجة ليستا الشيء نفسه — دقيقتان إضافيتان من التنظيم الدقيق ساوتا 23 نقطة IQ.
- التكلفة والنتيجة لا تتوافقان دائمًا. سجّلت جولة الـ$200 أعلى مقابل شريحة أصغر من حدّها.
- الموجّه جزء من النتيجة. جاءت أعلى نتيجة من موجّه مختلف قليلًا وأقصر — فالكلمات التي تختارها متغير أيضًا، لا ثابت. حين تقارن الوكلاء، قارن تعليماتهم قبل أن تثق بالأرقام.
إذن، لا، هذا ليس تصنيفًا علميًا للعقول الاصطناعية. لكن إن كان السؤال "ما معدل ذكاء وكيلك في اختبار ويب بصري غريب؟"، فجوابي بسيط.
أسئلة شائعة سريعة
أيُّ وكيل برمجة حصل على أعلى معدل ذكاء في الاختبار؟
حصل Codex 5.5 على خطة الـ$200 على أعلى نتيجة، IQ 131. وحصل Codex 5.5 على خطة الـ$100 على IQ 124، وهي أفضل جولة مع التعليمات الأكثر صرامة باختيار سن 30.
هل كان هذا معيارًا علميًا لوكلاء الذكاء الاصطناعي؟
لا. كانت تجربة عملية واقعية باستخدام اختبار ذكاء بصري عام واحد، الغرض منها مقارنة السلوك والوقت والتكلفة والتعامل مع المتصفح وأسلوب حل المشكلات البصرية.
ما الذي بدا أنه الأهم للحصول على نتيجة عالية؟
الجولات الأقوى نظّمت صور الألغاز أولًا، وكبّرت الأسئلة الصعبة، وراجعت الإجابات غير المؤكدة قبل الإرسال.